If there's one thing that's true about the word "blockchain", it's that
these days people have strong opinions about it.
Open your social media feed and you'll see people either heaping praises
on blockchains, calling them the saviors of humanity, or condemning them
as destroying and burning down the planet and making the rich richer
and the poor poorer and generally all the other kinds of fights that
people like to have about capitalism (also a quasi-vague word
occupying some hotly contested mental real estate).
There are good reasons to hold opinions about various aspects of what
are called "blockchains", and I too have some pretty strong opinions
I'll be getting into in a followup article.
The followup article will be about "cryptocurrencies", which many people
also seem to think of as synonymous with "blockchains", but this isn't
particularly true either, but we'll deal with that one then.
In the meanwhile, some of the fighting on the internet is kind of
confusing, but even more importantly, kind of confused.
Some of it might be what I call "sportsballing": for whatever reason,
for or against blockchains has become part of your local sportsball
team, and we've all got to be team players or we're gonna let the local
team down already, right?
And the thing about sportsballing is that it's kind of arbitrary and
it kind of isn't, because you might pick a sportsball team because you
did all your research or you might have picked it because that just
happens to be the team in your area or the team your friends like, but
god almighty once you've picked your sportsball team let's actually not
talk against it because that might be giving in to the other side.
But sportsballing kind of isn't arbitrary either because it tends to
be initially connected to real communities of real human beings and
there's usually a deeper cultural web than appears at surface level,
so when you're poking at it, it appears surface-level shallow but
there are some real intricacies beneath the surface. (But anyway, go
sportsball team.)
But I digress.
There are important issues to discuss, yet people aren't really
discussing them, partly because people mean different things.
"Blockchain" is a strange term that encompasses a wide idea space,
and what people consider or assume essential to it vary just as
widely, and thus when two people are arguing they might not even be
arguing about the same thing.
So let's get to unpacking.
"Blockchain" as handwaving towards decentralized networks in general
Years ago I was at a conference about decentralized networked
technology, and I was having a conversation with someone I had just met.
This person was telling me how excited they were about
blockchains... finally we have decentralized network designs, and so
this seems really useful for society!
I paused for a moment and said yes, blockchains can be useful for some
things, though they tend to have significant costs or at least
tradeoffs. It's good that we also have other decentralized network
technology; for example, the ActivityPub
standard I was involved in had no blockchains but did rely on the
much older "classic actor model."
"Oh," the other person said, "I didn't know there were other kinds of
decentralized network designs. I thought that 'blockchain' just meant
'decentralized network technology'."
It was as if a light had turned on and illuminated the room for me. Oh!
This explained so many conversations I had been having over the years.
Of course... for many people, blockchains like Bitcoin were the first
ever exposure they had (aside from email, which maybe they never gave
much thought to as being decentralized) of something that involved
a decentralized protocol. So for many people, "blockchain" and
"decentralized technology" are synonyms, if not in technical design,
but in terms of understanding of a space.
Mark S. Miller, who was standing next to me, smiled and gave a very
interesting followup: "There is only one case in which you need a
blockchain, and that is in a decentralized system which needs to
converge on a single order of events, such as a public ledger
dealing with the
double spending problem."
Two revelations at once. It was a good conversation... it was a good
start.
But I think there's more.
Blockchains are the "cloud" of merkle trees
As time has gone on, the discourse over blockchains has gotten more
dramatic. This is partly because what a "blockchain" is hasn't been
well defined.
All terminology exists on an ever-present battle between
fuzziness and crispness,
with some terms being much clearer than others.
The term "boolean" has a fairly crisp definition in computer science,
but if I ask you to show me your "stove", the device you show me today
may be incomprehensible to someone's definition a few centuries ago,
particularly in that today it might not involve fire.
Trying to define as in terms of its functionality can also cause
confusion: if I asked you to show me a stove, and you showed me a
computer processor or a car engine, I might be fairly confused, even
though technically people enjoy showing off that they can cook eggs on
both of these devices when they get hot enough.
(See also: Identity is a Katamari, language is a Katamari explosion.)
Still, some terms are fuzzier than others, and as far as terms go,
"blockchain" is quite fuzzy.
Hence my joke: "Blockchains are the 'cloud' of merkle trees."
This ~joke tends to get a lot of laughs out of a particular kind of
audience, and confused looks from others, so let me explain.
The one thing everyone seems to agree on is that it's a "chain of
blocks", but all that really seems to mean is that it's a
merkle tree... really,
just an immutable datastructure where one node points at the parent node
which points at the parent node all the way up.
The joke then is not that this merkle tree runs on a cloud, but that
"cloud computing" means approximately nothing: it's marketing speak for
some vague handwavey set of "other peoples' computers are doing
computation somewhere, possibly on your behalf sometimes."
Therefore, "cloud of merkle trees" refers to the vagueness of the
situation.
(As everyone knows, jokes are funnier when fully explained, so I'll
turn on my "STUDIO LAUGHTER" sign here.)
So, a blockchain is a chain of blocks, ie a merkle tree, and I mean,
technically speaking, that means that Git is a
blockchain (especially if the commits are signed), but when you see
someone arguing on the internet about whether or not blockchains are
"good" or "bad", they probably weren't thinking about git, which aside
from having a high barrier of entry in its interface and some concerns
about the hashing algorithm used, isn't really something likely to
drag you into an internet flamewar.
"Blockchain" is to "Bitcoin" what "Roguelike" is to "Rogue"
These days it's common to see people either heaping praises on
blockchains or criticizing them, and those people tend to be shouting
past one another.
I'll save unpacking that for another post.
In the meanwhile though, it's worth noting that people might not be
talking about the same things.
What isn't in doubt is whether or not
Bitcoin
is a blockchain... trying to understand and then explore the problem
space around Bitcoin is what created the term "blockchain".
It's a bit like the video game genre of
roguelikes,
which started with the game
Rogue,
particularly explored and expanded upon in
NetHack,
and then suddenly exploding into the indie game scene as a "genre"
of its own.
Except the genre has become fuzzier and fuzzier as people have explored
the surrounding space.
What is essential?
Is a grid based layout essential?
Is a non-euclidean grid acceptable?
Do you have to provide an ascii or ansi art interface so people can play
in their terminals?
Dare we allow unicode characters?
What if we throw out terminals altogether and just play on a grid
of 2d pixelart?
What about 3d art?
What about permadeath?
What about the fantasy theme?
What about random level generation?
What are the key features
of a roguelike?
Well now we're at the point where I pick up a game like
Blazing Beaks
and it calls itself a
"roguelite",
which I guess is embracing the point that terminology has gotten extremely
fuzzy... this game feels more like
Robotron
than Rogue.
So... if "blockchain" is to Bitcoin what "roguelike" is to Rogue, then
what's essential to a blockchain?
Does the blockchain have to be applied to a financial instrument, or
can it be used to store updateable information about eg identity?
Is global consensus required?
Or what about a "trusted quorum" of nodes, such as in Hyperledger?
Is "mining" some kind of asset a key part of the system?
Is proof of work acceptable, or is proof of stake okay?
What about proof of space, proof of space-time, proof of pudding?
On top of all this, some of the terms around blockchains have been
absorbed as if into them.
For instance, I think to many people, "smart contract" means something
like "code which runs on a blockchain" thanks to Ethereum's major
adoption of the term, but the
E programming language
described "smart contracts" as the "likely killer app of distributed
capabilities" all the way
back in 1999,
and was
borrowing the term
from
Nick Szabo,
but really the same folks working on E had described many of those same
ideas in the Agoric Papers back in 1988.
Bitcoin wasn't even a thing at all until at least 2008, so depending on
how you look at it, "smart contracts" precede "blockchains" by one or
two decades.
So "blockchain" has somehow even rolled up terms outside of its space
as if within it.
(By the way, I don't think anyone has given a good and crisp definition
for "smart contract" either despite some of these people trying to give
me one, so let me give you one that I think is better and embraces its
fuzziness: "Smart contracts allow you to do the kinds of things you
might do with legal contracts, but relying on networked computation
instead of a traditional state-based legal system."
It's too bad more people also don't know about the huge role that Mark
Miller's "split contracts" idea plays into this space because that's
what makes the idea finally makes sense... but that's a conversation
for another time.)
(EDIT: Well, after I wrote this, Kate Sills lent me her
definition, which I think is the best one: "Smart contracts are
credible commitments using technology, and outside a state-provided
legal system." I like it!)
So anyway, the point of this whole section is to say that kind of like
roguelike, people are thinking of different things as essential to
blockchains.
Everyone roughly agrees on the jumping-off point of ideas but since
not everyone agrees from there, it's good to check in when we're having
the conversation.
Wait, you do/don't like this game because it's a roguelike?
Maybe we should check in on what features you mean.
Likewise for blockchains.
Because if you're blaming blockchains for burning down the planet, more
than likely you're not condemning signed git repositories (or at least,
if you're condemning them, you're probably doing so about it from an
aspect that isn't the fundamental datastructure... probably).
This is an "easier said than done" kind of thing though, because of
course, I'm kind of getting into some "in the weeds" level of details
here... but it's the "in the weeds" where all the substance of the
disagreements really are.
The person you are talking with might not actually even know or consider
the same aspects to be essential that you consider essential though,
so taking some time to ask which things we mean can help us lead to a
more productive conversation sooner.
"Blockchain" as an identity signal
First, a digression.
One thing that's kind of curious about the term
"virtue signal"
is that in general it tends to be used as a kind of virtue signal.
It's kind of like the word
hipster
in the previous decade, which weirdly seemed to be obsessively and
pejoratively used by people who resembled hipsters than anyone else.
Hence I used to make a joke called "hipster recursion", which is that
since hipsters seem more obsessesed with pejorative labeling of
hipsterism than anyone else, there's no way to call someone a "hipster"
without yourself taking on hipster-like traits, and so inevitably
even this conversation is N-levels deep into hipster recursion
for some numerical value of N.
"Virtue signaling" appears similar, but even more ironically so
(which is a pretty amazing feat given how much of hipsterdom seems to
surround a kind of inauthentic irony).
When I hear someone say "virtue signaling" with a kind of sneer, part
of that seems to be acknowledging that other people are sending signals
merely to impress others that they are some kind of the same group but
it seems as if it's being raised as in a
you-know-and-I-know-that-by-me-acknowledging-this-I'm-above-virtue-signaling
kind of way.
Except that by any possible definition of virtue signaling, the above
appears to be a kind of virtue signaling, so now we're into virtue
signaling recursion.
Well, one way to claw our way out of the rabbithole of all this is to
drop the pejorative aspect of it and just acknowledge that signaling
is something that everyone does.
Hence me saying "identity signaling" here.
You can't really escape identity signaling, or even sportsballing, but
you can acknowledge that it's a thing that we all do, and there's a
reason for it: people only have so much time to find out information
about each other, so they're searching for clues that they might align
and that, if they introduce you to their peer group, that you might
align with them as well, without access to a god-like view of the
universe where they know exactly what you think and exactly what
kinds of things you've done and exactly what way you'll behave in
the future or whether or not you share the same values.
(After all, what else is
virtue ethics
but an ethical framework that takes this in its most condensed form as
its foundation?)
But it's true that at its worst, this seems to result in shallow, quick,
judgmental behavior, usually based on stereotypes of the other side...
which can be unfortunate or unfair to whomever is being talked about.
But also on the flip side, people also do identity signal to each other
because they want to create a sense of community and bonding.
That's what a lot of culture is.
It's worth acknowledging then that this occurs, recognizing its use and
limitations, without pretending that we are above it.
So wow, that's quite a major digression, so now let's get back to
"identity signaling".
There is definitely a lot of identity signaling that tends to happen
around the word "blockchain", for or against.
Around the critiques of the worst of this, I tend to agree: I find much
of the machismo hyper-white-male-privilege that surrounds some of the
"blockchain" space uncomfortable or cringey.
But I also have some close friends who are not male and/or are people
of color and those ones tend to actually suffer the worst of it from
these communities internally, but also seem to find things of value in
them, but particularly seem to feel squeezed externally when the field
is reduced to these kinds of (anti?-)patterns.
There's something sad about that, where I see on the one hand friends
complaining about blockchain from the outside on behalf of people who
on the inside seem to be both struggling internally but then kind of
crushed by being lumped into the same identified problems externally.
This is hardly a unique problem but it's worth highlighting for a moment
I think.
But anyway, I've taken a bunch of time on this, more than I care to,
maybe because (irony again?) I feel that too much of public conversation
is also hyperfocusing on this aspect... whether there's a subculture
around blockchain, whether or not that subculture is good or bad, etc.
There's a lot worthwhile in unpacking this discourse-wise, but some of
the criticisms of blockchains as a technology (to the extent it even
is coherently one) seem to get lumped up into all of this.
It's good to provide thoughtful cultural critique, particularly one
which encourages healthy social change.
And we can't escape identity signaling.
But as someone who's trying to figure out what properties of networked
systems we do and don't want, I feel like I'm trying to navigate the
machine and for whatever reason, my foot keeps getting caught in the
gears here.
Well, maybe that itself is pointing to some architectural mistakes,
but socially architectural ones.
But it's useful to also be able to draw boundaries around it so that
we know where this part of the conversation begins and ends.
"Blockchain" as "decentralized centralization" (or "decentralized convergence")
One of the weird things about people having the idea of "blockchains" as
being synonymous with "decentralization" is that it's kind of both very
true and very untrue, depending on what abstraction layer you're
looking at.
For a moment, I'm going to frame this in harsh terms: blockchains are
decentralized centralization.
What?
How dare I!
You'll notice that this section is in harsh contrast to the
"blockchain as handwaving towards decentralized networks in general"
section... well, I am acknowledging the decentralized aspect of it,
but the weird thing about a blockchain is that it's a decentralized
set of nodes converging on (creating a centrality of!) a single
abstract machine.
Contrast with
classic actor model
systems like
CapTP
in Spritely Goblins,
or as less good examples
(because they aren't quite as behavior-oriented as they are
correspondence-oriented, usually)
ActivityPub
or
SMTP
(ie, email).
All of these systems involve decentralized computation and collaboration
stemming from sending messages to actors (aka "distributed objects").
Of CapTP this is especially clear and extreme: computations happen in
parallel across many collaborating machines (and even better, many
collaborating objects on many collaborating machines), and the behavior
of other machines and their objects is often even opaque to you.
(CapTP survives this in a beautiful way, being able to do well on
anonymous, peer to peer, "mutually suspicious" networks.
But maybe read my
rambling thoughts about CapTP
elsewhere.)
While to some degree there are some very
clever
tricks
in the world of cryptography where you may be able to get back some of
the opacity, this tends to be very expensive, adding an expensive
component to the already inescapable additional expenses of a
blockchain.
A multi-party blockchain with some kind of consensus
will always, by definition be slower than a single machine operating
alone.
If you are irritated by this framing: good.
It's probably good to be irritated by it at least once, if you can
recognize the portion of truth in it.
But maybe that needs some unpacking to get there.
It might be better to say "blockchains are decentralized convergence",
but I have some other phrasing that might be helpful.
"Blockchain" as "a single machine that many people run"
There's value in having a single abstract machine that many people run.
The most famous source of value is in the "double spending problem".
How do we make sure that when someone has money, they don't spend that
money twice?
Traditional accounting solves this with a linear, sequential ledger,
and it turns out that the right solution boils down to the same thing
in computers.
Emphasis on sequential: in order to make sure money balances out
right, we really do have to be able to order things.
Here's the thing though: the double spending problem was in a sense
solved in terms of single-computers a long time ago in the object
capability security community.
Capability-based Financial Instruments
was written about a decade before blockchains even existed and
showed off how to make a "mint" (kind of like a fiat-currency bank)
that can be implemented in about 25 lines of code in the right
architecture (I've ported it to Goblins,
for instance) and yet has both distributed accounts and is robust
against corruption on errors.
However, this seems to be running on a "single-computer based
machine", and again operates like a fiat currency.
Anyone can create their own fiat currency like this, and they are
cheap, cheap, cheap (and fast!) to make.
But it does rely on sequentiality to some degree to operate correctly
(avoiding a class of attacks called "re-entrancy attacks").
But this "single-computer based machine" might bother you for a couple
reasons:
We might be afraid the server might crash and service will be
interrupted, or worse yet, we will no longer be able to access our
accounts.
Or, even if we could trade these on an open market, and maybe
diversify our portfolio, maybe we don't want to have to trust a
single operator or even some appointed team of operators... maybe we
have a lot of money in one of these systems and we want to be sure
that it won't suddenly vanish due to corruption.
Well, if our code operates deterministically, then what if from the
same initial conditions (or saved snapshot of the system) we replay
all input messages to the machine?
Functional programmers know: we'll end up with the same result.
So okay, we might want to be sure this doesn't accidentally get
corrupted, maybe for backup reasons.
So maybe we submit the input messages to two computers, and then
if one crashes, we just continue on with the second one until the
other comes up, and then we can restore the first one from the
progress the second machine made while the first one was down.
Oh hey, this is already technically a blockchain.
Except our trust model is that we implicitly trust both machines.
Hm.
Maybe we're now worried that we might have top-down government
pressure to coerce some behavior on one of our nodes, or maybe we're
worried that someone at a local datacenter is going to flip some bits
to make themselves rich.
So we actually want to spread this abstract machine out over three
countries.
So okay, we do that, and now we set a rule agreeing on what all the
series of input messages are... if two of three nodes agree, that's
good enough.
Oh hey look, we've just invented the "small-quorum-style"
blockchain/ledger!
(And yes, you can wire up Goblins
to do just this; a hint as to how is seen in the
Terminal Phase time travel demo.
Actually, let's come back to that later.)
Well, okay.
This is probably good enough for a private financial asset, but what
about if we want to make something more... global?
Where nobody is in charge!
Well, we could do that too.
Here's what we do.
First, we need to prevent a "swarming attack" (okay, this is
generally called a "sybil attack" in the literature, but for a
multitude of reasons I won't get into, I don't like that term).
If a global set of peers are running this single abstract machine,
we need to make sure there aren't invocations filling up the system
with garbage, since we all basically have to keep that information
around.
Well... this is exactly where those proof-of-foo systems come in
the first time; in fact Proof of Work's origin is in something
called Hashcash which
was designed to add "friction" to disincentivize spam for email-like
systems.
If we don't do something friction-oriented in this category, our
ledger is going to be too easily filled with garbage too fast.
We also need to agree on what the order of messages is, so we
can use this mechanism in conjuction with a consensus algorithm.
When are new units of currency issued?
Well, in our original mint example, the person who set up the mint
was the one given the authority to make new money out of thin air
(and they can hand out attenuated versions of that authority to
others as they see fit).
But what if instead of handing this capability out to individuals
we handed it out to anyone who can meet an abstract requirement?
For instance, in zcap-ld
an invoker can be any kind of entity which is specified with
linked data proofs,
meaning those entities can be something other than a single key...
for instance, what if we delegated to an abstract invoker that was
specified as being "whoever can solve the state of the machine's current
proof-of-work puzzle"?
Oh my gosh!
We just took our 25-line mint and extended it for mining-style
blockchains.
And the fundamental design still applies!
With these two adjustments, we've created a "public blockchain" akin
to bitcoin.
And we don't need to use proof-of-work for either technically...
we could swap in different mechanisms of friction / qualification.
If the set of inputs are stored as a merkle tree, then all of the
system types we just looked at are technically blockchains:
A second machine as failover in a trusted environment
Three semi-trusted machines with small-scale private consensus
A public blockchain without global trust, with swarming-attack
resistance and an interesting abstract capability accessible
to anyone who can meet the abstract requirement (in this case,
to issue some new currency).
The difference for choosing any of the above is really a question of:
"what is your trust/failover requirements?"
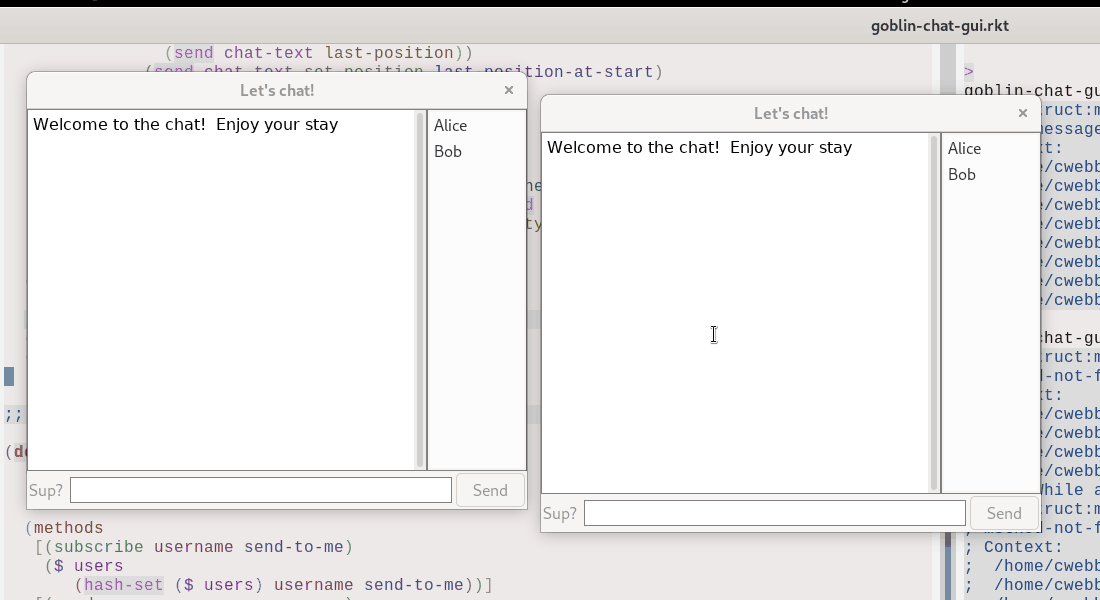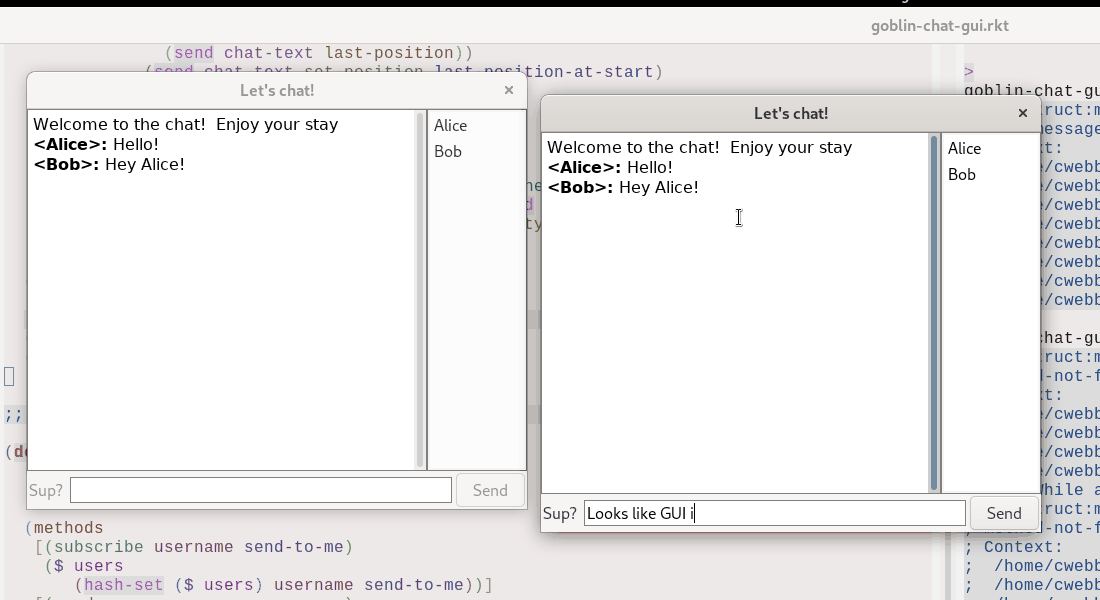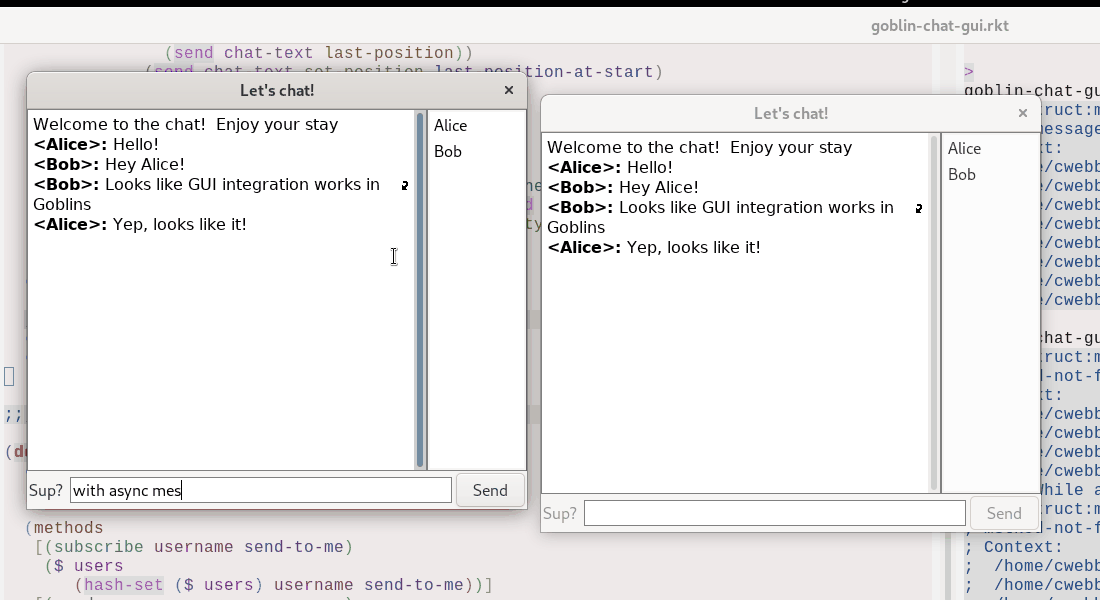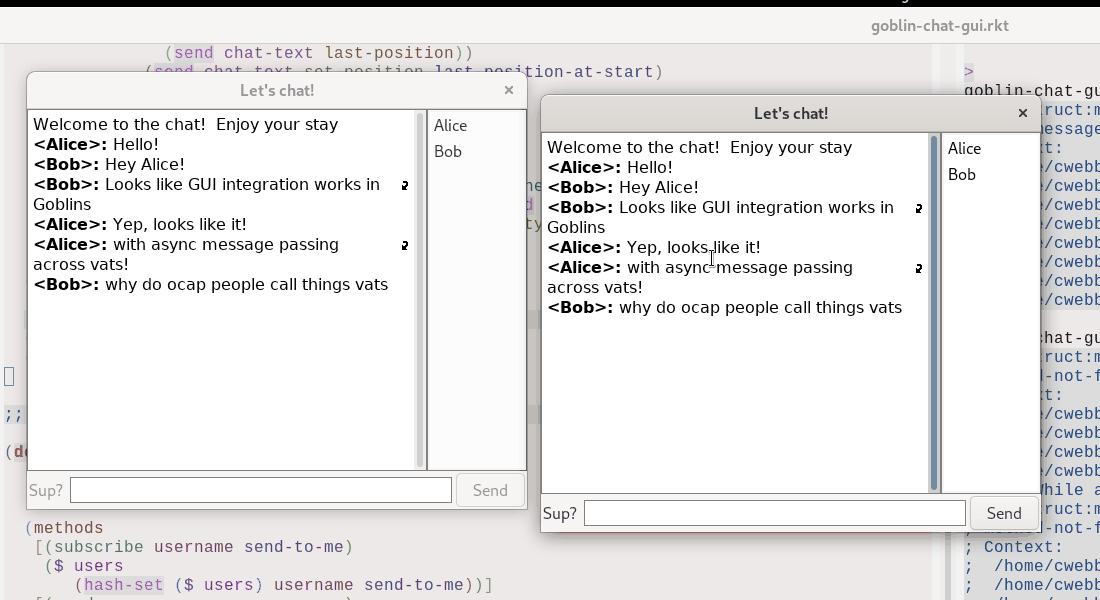
Blockchains as time travel plus convergent inputs
If this doesn't sound believable to you, that you could create
something like a "public blockchain" on top of something like Goblins
so easily, consider how we might extend
time travel in Terminal Phase
to add multiplayer.
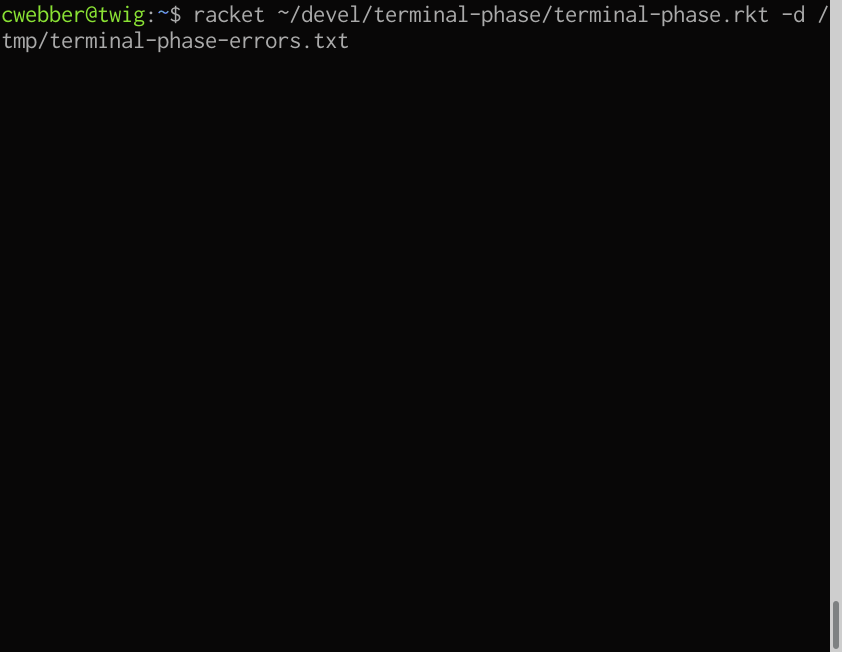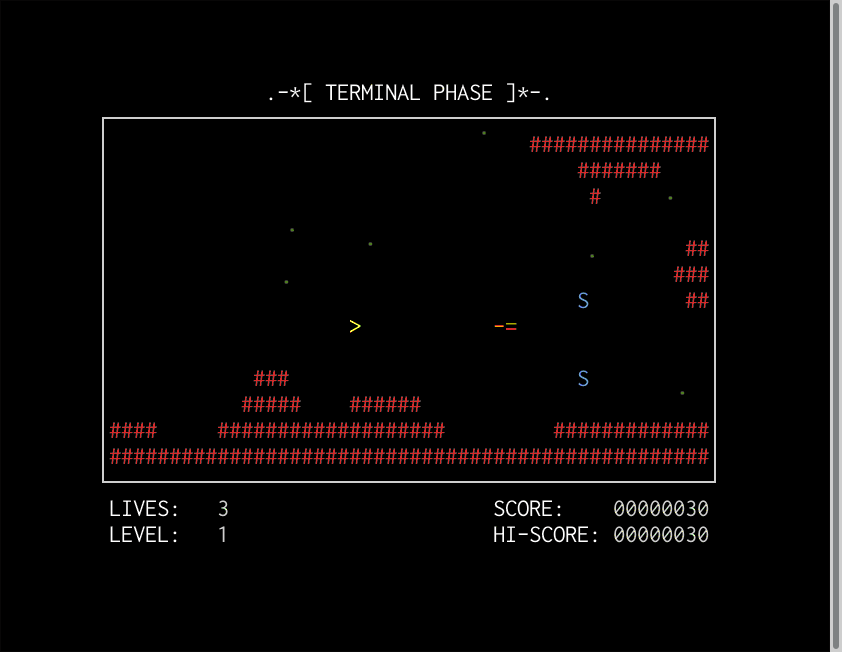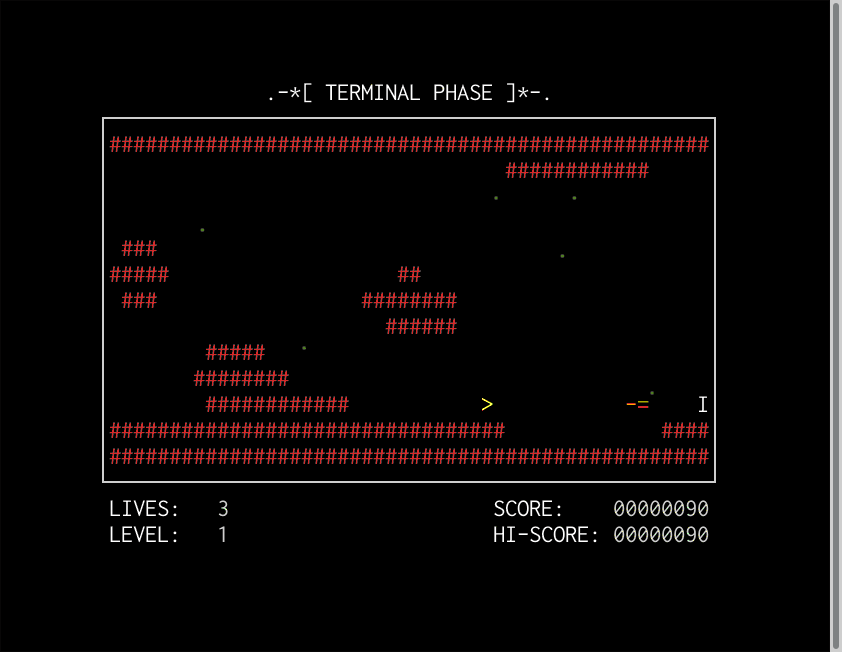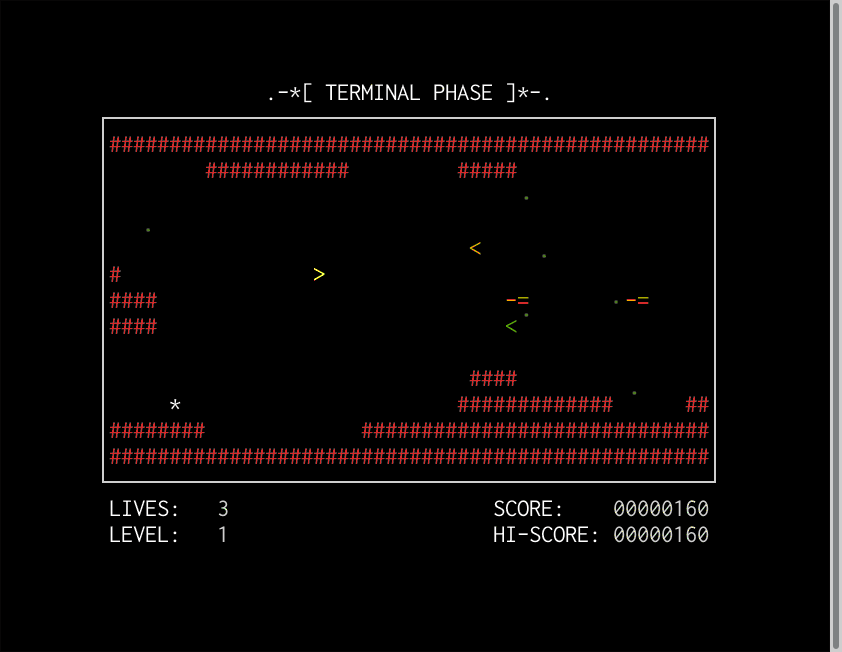
As a reminder, here's an image:
Now, a secret thing about Terminal Phase is that the gameplay is
deterministic (the random starfield in the background is not, but the
gameplay is) and runs on a fixed frame-rate.
This means that given the same set of keyboard inputs, the game will
always play the same, every time.
Okay, well let's say we wanted to hand some way for someone to replay
our last game.
Chess games can be fully replayed with a very
condensed syntax,
meaning that merely handing someone a short list of codes they can
precisely replay the same game, every time, deterministically.
Well okay, as a first attempt at thinking this through, what if for
some game of Terminal Phase I played we wrote down each keystroke I
entered on my keyboard, on every tick of the game?
Terminal Phase runs at 30 ticks per second.
So okay, if you replay these, each one at 30 ticks per second, then
yeah, you'd end up with the same gameplay every time.
It would be simple enough for me to encode these as a linked list
(cons, cons, cons!) and hand them to you.
You could descend all the way to the root of the list and start
playing them back up (ie, play the list in reverse order) and you'd
get the same result as I did.
I could even stream new events to you by giving you new items to
tack onto the front of the list, and you could "watch" a game I
was playing live.
So now imagine that you and I want to play Terminal Phase together
now, over the network.
Let's imagine there are two ships, and for simplicity, we're playing
cooperatively.
(The same ideas
can be extended to competitive,
but for narrating how real-time games work it's easier to to start
with a cooperative assumption.)
We could start out by wiring things up on the network so that I am
allowed to press certain keys for player 1 and you are allowed to
press certain keys for player 2.
(Now it's worth noting that a better way to do this doesn't involve
keys on the keyboard but capability references, and really that's
how we'd do things if we were to bring this multiplayer idea live, but
I'm trying to provide a metaphor that's easy to think about without
introducing the complicated sounding kinds of terms like "c-lists" and
"vat turns" that we ocap people seem to like.)
So, as a first attempt, maybe if we were playing on a local area
network or something, we could synchronize at every game tick: I share
my input with you and you share yours, and then and only then do both
of our systems actually input them into that game-tick's inputs.
We'll have achieved a kind of "convergence" as to the current game state
on every tick.
(EDIT: I wrote "a kind of consensus" instead of "a kind of
convergence" originally, and that was an error, because it misleads
on what consensus algorithms tend to do.)
Except this wouldn't work very well if you and I were living far away
from each other and playing over the internet... the lag time for
doing this for every game tick might slow the system to a crawl...
our computers wouldn't get each others' inputs as fast as the game was
moving along, and would have to pause until we received each others'
moves.
So okay, here's what we'll do.
Remember the time-travel GUI above?
As you can see, we're effectively restoring from an old snapshot.
Oh! So okay.
We could save a snapshot of the game every second, and then both get
each other our inputs to each other as fast as we can, but knowing
it'll lag.
So, without having seen your inputs yet, I could move my ship up and
to the right and fire (and send that I did that to you).
My game would be in a "dirty state"... I haven't actually seen what
you've done yet.
Now suddenly I get the last set of moves you did over the network...
in the last five frames, you move down and to the left and fire.
Now we've got each others' inputs... what our systems can do is
secretly time travel behind the scenes to the last snapshot, then
fast forward, replaying both of our inputs on each tick up until the
latest state where we've both seen each others' moves (but we wouldn't
show the fast forward process, we'd just show the result with the
fast forward having been applied).
This can happen fast enough that I might see your ship jump forward
a little, and maybe your bullet will kill the enemy instead of mine
and the scores shift so that you actually got some points that
for a moment I thought I had, but this can all happen in realtime
and we don't need to slow down the game at all to do it.
Again, all the above can be done, but with actual wiring of
capabilities instead of the keystroke metaphor... and actually, the
same set of ideas can be done with any kind of system, not just
a game.
And oh hey, technically, technically, technically if we both hashed
each of our previous messages in the linked list and signed each one,
then this would qualify as a merkle tree and then this would also
qualify as a blockchain... but wait, this doesn't have anything to do
with cryptocurrencies!
So is it really a blockchain?
"Blockchain" as synonym for "cryptocurrency" but this is wrong and don't do this one
By now you've probably gotten the sense that I really was annoyed with
the first section of "blockchain" as a synonym for "decentralization"
(especially because blockchains are decentralized centralization/convergence)
and that is completely true.
But even more annoying to me is the synonym of "blockchain" with
"cryptocurrency".
"Cryptocurrency" means "cryptographically based currency" and it is
NOT synonymous with blockchains.
Digicash precedes blockchains
by a dramatic amount, but it is a cryptocurrency.
The "simple mint" type system also precedes blockchains and while it
can be run on a blockchain, it can also run on a solo
computer/machine.
But as we saw, we could perceive multiplayer Terminal Phase as
technically, technically a blockchain, even though it has nothing to do with
currencies whatsoever.
So again a blockchain is just a single, abstract, sequential machine,
run by multiple parties.
That's it.
It's more general than cryptocurrencies, and it's not exclusive to
implementing them either.
One is a kind of programming-plus-cryptography-use-case
(cryptocurrencies), the other one is a kind of abstracted machine
(blockchains).
So please.
They are frequently combined, but don't treat them as the same thing.
Blockchains as single abstract machines on a wider network
One of my favorite talks is Mark Miller's
Programming Secure Smart Contracts
talk.
Admittedly, I like it partly because it well illustrates some of the
low-level problems I've been working on, and that might not be as
useful to everyone else.
But it has this lovely diagram in it:
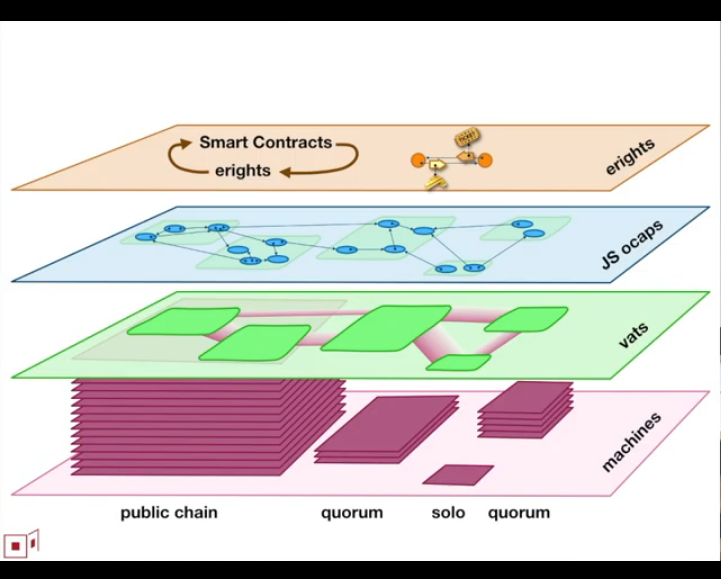
This is better understood by watching the video, but the abstraction
layers described here are basically as follows:
"Machines" are the lowest layer of abstraction on the network, but
there a variety of kinds of machines.
Public blockchains are one, quorum blockchains are another, solo
computer machines yet another (and the simplest case, too).
What's interesting then is that we can see public chains and quorums
abstractly demonstrated as machines in and of themselves... even though
they are run by many parties.
Vats are the next layer of abstraction, these are basically the
"communicating event loops"... actors/objects live inside them,
and more or less these things run sequentially.
Replace "JS ocaps" with "language ocaps" and you can see actors/objects
in both Javascript and Spritely living here.
Finally, at the top are "erights" and "smart contracts", which feed
into each other... "erights" are "exclusive electronic rights", and
"smart contracts" are generally patterns of cooperation involving
achieving mutual goals despite suspicion, generally involving the
trading of these erights things (but not necessarily).
Okay, well cool!
This finally explains the worldview I see blockchains on.
And we can see a few curious things:
The "public chain" and "quorum" kinds of machines still boil down
to a single, sequential abstract machine.
Object connections exist between the machines... ocap security.
No matter whether it's run by a single computer or multiple.
Public blockchains, quorum blockchains, solo-computer machines
all talk to each other, and communicate between object references
on each other.
Blockchains are not magical things.
They are abstracted machines on the network.
Some of them have special rules that let whoever can prove they qualify
for them access some well-known capabilities, but really they're just
abstracted machines.
And here's an observation: you aren't ever going to move all
computation to a single blockchain.
Agoric's CEO, Dean Tribble,
explained beautifully why on a recent podcast:
One of the problems with Ethereum is it is as tightly coupled as
possible.
The entire world is a single sequence of actions that runs on a
computer with about the power of a cell phone.
Now, that's obviously hugely valuable to be able to do commerce in a
high-integrity fashion, even if you can only share a cell phone's
worth of compute power with the entire rest of the world.
But that's clearly gonna hit a brick wall.
And we've done lots of large-scale distributed systems whether
payments or cyberspace or coordination, and the fundamental model
that covers all of those is
islands of sequential programming in a sea of asynchronous communication.
That is what the internet is about, that's what the interchain is about,
that's what physics requires you to do if you want a system to scale.
Put this way, it should be obvious: are we going to replace the entire
internet with something that has the power of a cell phone?
To ask the question is to know the answer: of course not.
Even when we do admit blockchain'y systems into our system, we're going
to have to have many of them communicating with each other.
Blockchains are just machines that many people/agents run.
That's it.
Some of these are encoded with some nice default programming to do
some useful things, but all of them can be done in non-blockchain
systems because
communicating islands of sequential processes is the generalization.
You might still want a blockchain, ie you might want multiple parties
running one of those machines as a shared abstract machine, but
how you configure that blockchain from there might depend on your
trust and integrity requirements.
What do I think of blockchains?
I've covered a wide variety of perspectives of "what is a blockchain"
in this article.
On the worse end of things are the parts involving hand-wavey
confusion about decentralization, mistaken ideas of them being tied to
cryptocurrencies, marketing hype, cultural assumptions, and some real,
but not intrinsic, cultural problems.
In the middle, I am particularly keen on highlighting the similarity
between the term "blockchain" and the term "roguelike", how both of
them might boil down to some key ideas or not, but more importantly
they're both a rough family of ideas that diverge from one highly
influential source (Bitcoin and Rogue respectively).
This is also the source of much of the "shouting past each other",
because many people are referring to different components that they
view as essential or inessential.
Many of these pieces may be useful or harmful in isolation, in small
amounts, in large amounts, but much of the arguing (and posturing)
involves highlighting different things.
On the better end of things is a revelation, that blockchains are just
another way of abstracting a computer so that multiple parties can run
it.
The particular decisions and use cases layered on top of this
fundamental design are highly variant.
Having made the waters clear again, we could muddy them.
A friend once tried to convince me that all computers are
technically blockchains, that blockchains are the generalization of
computing, and the case of a solo computer is merely one where a
blockchain is run only by one party and no transaction history or old
state is kept around.
Maybe, but I don't think this is very useful.
You can go in either direction, and I think the time travel and
Terminal Phase section maybe makes that clear to me, but I'm not so
sure how it lands with others I suppose.
But a term tends to be useful in terms of what it introduces, and
calling everything a blockchain seems to make the term even less
useful than it already is.
While a blockchain could be one or more parties running a sequential
machine as the generalization, I suggest we stick to two or more.
Blockchains are not magic pixie dust, putting something on a
blockchain does not make it work better or more
decentralized... indeed, what a blockchain really does is converging
(or re-centralizing) a machine from a decentralized set of computers.
And it always does so with some cost, some set of overhead...
but what those costs and overhead are varies depending on what the
configuration decisions are.
Those decisions should always stem from some careful thinking about
what those trust and integrity needs are... one of the more
frustrating things about blockchains being a technology of great
hype and low understanding is that such care is much less common than
it should be.
Having a blockchain, as a convergent machine, can be useful.
But how that abstracted convergent machine is arranged can diverge
dramatically; if we aren't talking about the same choices, we might
shout past each other.
Still, it may be an unfair ask to request that those without a deep
technical background go into technical specifics, and I recognize
that, and in a sense there can be some amount gained from speaking
towards broad-sweeping, fuzzy sets and the patterns they seem to be
carrying.
A gut-sense assertion from a set of loosely observed behaviors can be
a useful starting point.
But to get at the root of what those gut senses actually map to, we
will have to be specific, and we should encourage that specificity
where we can (without being rude about it) and help others see those
components as well.
But ultimately, as convergent machines, blockchains will not operate
alone.
I think the system that will hook them all together
should be CapTP.
But no matter the underlying protocol abstraction, blockchains
are just abstract machines on the network.
Having finally disentangled what blockchains are, I think soon I
would like to move onto what cryptocurrencies are.
Knowing that they are not necessarily tied to blockchains opens us
up to considering an ecosystem, even an interoperable and exchangeable
one, of varying cryptographically based financial instruments, and
the different roles and uses they might play.
But that is another post of its own, for whenever I can get to it,
I suppose.
ADDENDUM: After writing this post, I had several conversations
with several blockchain-oriented people.
Each of them roughly seemed to agree that Bitcoin was roughly the
prototypical "blockchain", but each of them also seemed to highlight
different things they thought were "essential" to what a "blockchain"
is: some kinds of consensus algorithms being better than others, that
kinds of social arrangements are enabled, whether transferrable
assets are encoded on the chain, etc.
To start with, I feel like this does confirm some
of the premise of this post, that Bitcoin is the starting point, but
like Rogue and "roguelikes", "blockchains" are an exploration space
stemming from a particular influential technical piece.
However my friend Kate Sills (who also gave me a much better
definition for "smart contracts", added above) highlighted something
that I hadn't talked about much in my article so far, which I do agree
deserves expansion.
Kate said: "I do think there is something huge missing from your
piece. Bitcoin is amazing because it aligns incentives among actors
who otherwise have no goals in common."
I agree that there's something important here, and this definition of
"blockchain" maybe does explain why while from a computer science
perspective, perhaps signed git trees do resemble blockchains, they
don't seem to fit within the realm of what most people are thinking
about... while git might be a tool used by several people with aligned
incentives, it is not generally itself the layer of
incentive-alignment.